Installation Guide
Overview
This is tutorial describing installation steps of CFEngine High Availability feature. It is suitable for both upgrading existing CFEngine installations to HA and for installing HA from scratch. Before starting installation we strongly recommend reading CFEngine High Availability overview. More detailed information can be found here.
Installation procedure
As with most High Availability systems, setting it up requires carefully following a series of steps with dependencies on network components. The setup can therefore be error-prone, so if you are a CFEngine Enterprise customer we recommend that you contact support for assistance if you do not feel 100% comfortable of doing this on your own.
Please also make sure you are having valid HA licenses for passive hub so that it will be able to handle all your CFEngine clients in case of failover.
Hardware configuration and OS pre-configuration steps
- CFEngine 3.6.2 hub package for RHEL6 or CentOS6.
- We recommend selecting dedicated interface used for PostgreSQL replication and optionally one for heartbeat.
- We recommend having one shared IP address assigned for interface where MP is accessible (optionally) and one where PostgreSQL replication is configured (mandatory).
- Both active and passive hub machines must be configured so that host names are different.
- Basic hostname resolution works (hub names can be placed in /etc/hosts or DNS configured).
Example configuration used in this tutorial
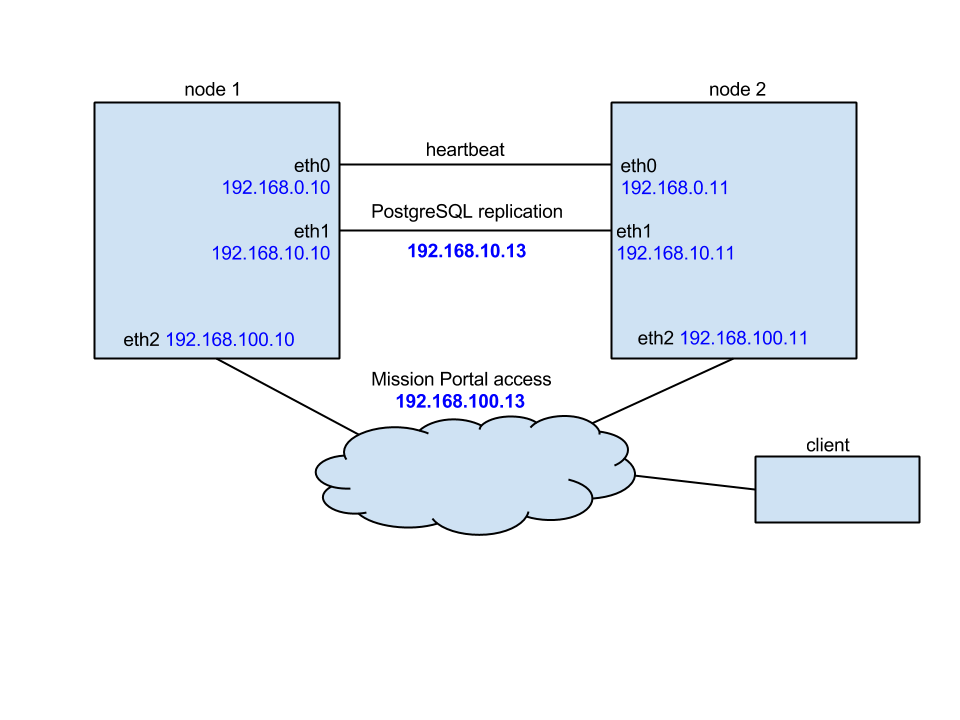
In this tutorial we are using following network configuration:
- Two nodes acting as active and passive where active node name is node1 and passive node name is node2.
- Each node having three NICs so that eth0 is used for heartbeat, eth1 is used for PostgreSQL replication and eth2 is used for MP and bootstrapping clients.
- IP addresses configured as follows:
| Node | eth0 | eth1 | eth2 |
|---|---|---|---|
| node1 | 192.168.0.10 | 192.168.10.10 | 192.168.100.10 |
| node2 | 192.168.0.11 | 192.168.10.11 | 192.168.100.11 |
| cluster shared | --- | 192.168.10.13 | 192.168.100.13 |
Detailed network configuration is shown on the picture below:
Installing cluster management tools
Before you begin you should have corosync (version 1.4.1 or higher) and pacemaker (version 1.1.10-14.el6_5.3 or higher) installed on both nodes. For your convenience we also recommend having crmsh installed. Detailed instructions how to install and set up all components are accessible here and here.
Once pacemaker and corosync are successfully installed on both nodes please follow steps below to set up it as needed by CFEngine High Availability.
IMPORTANT: please carefully follow the indicators describing if given step should be performed on active, passive or both nodes.
Configure corosync ( active and passive ):
echo "START=yes" > /etc/default/corosyncAdd pacemaker support ( active and passive ):
echo "service { # Load the Pacemaker Cluster Resource Manager ver: 1 name: pacemaker }" > /etc/corosync/service.d/pacemakerCreate corosync cluster configuration ( active and passive ):
cp /etc/corosync/corosync.conf.example /etc/corosync/corosync.conf- Find line with
bindnetaddr:and set to network address of interface used for cluster heartbeat (e.g.bindnetaddr: 192.168.1.0). - Configure
mcastaddr:andmcastport:if defaults are conflicting with other components placed in your network.
NOTE: If for some reason multicast is not supported by your network configuration (most times you need multicast broadcasting to be explicitly switched on) it is possible to use unicast configuration. For more details please refer corosync configuration guide.
Modify content of /usr/lib/ocf/resource.d/heartbeat/pgsql to contain CFEngine related configuration ( active and passive ):
# Defaults OCF_RESKEY_pgctl_default=/var/cfengine/bin/pg_ctl OCF_RESKEY_psql_default=/var/cfengine/bin/psql OCF_RESKEY_pgdata_default=/var/cfengine/state/pg/data OCF_RESKEY_pgdba_default=cfpostgres OCF_RESKEY_pghost_default="" OCF_RESKEY_pgport_default=5432 OCF_RESKEY_start_opt_default="" OCF_RESKEY_pgdb_default=template1 OCF_RESKEY_logfile_default=/dev/null OCF_RESKEY_stop_escalate_default=30 OCF_RESKEY_monitor_user_default="" OCF_RESKEY_monitor_password_default="" OCF_RESKEY_monitor_sql_default="select now();" OCF_RESKEY_check_wal_receiver_default="false" # Defaults for replication OCF_RESKEY_rep_mode_default=none OCF_RESKEY_node_list_default="" OCF_RESKEY_restore_command_default="" OCF_RESKEY_archive_cleanup_command_default="" OCF_RESKEY_recovery_end_command_default="" OCF_RESKEY_master_ip_default="" OCF_RESKEY_repuser_default="cfpostgres" OCF_RESKEY_primary_conninfo_opt_default="" OCF_RESKEY_restart_on_promote_default="false" OCF_RESKEY_tmpdir_default="/var/cfengine/state/pg/tmp" OCF_RESKEY_xlog_check_count_default="3" OCF_RESKEY_crm_attr_timeout_default="5" OCF_RESKEY_stop_escalate_in_slave_default=30Run corosyn and pacemaker to check if both cluster nodes are seen each other ( active and passive ):
/etc/init.d/corosync start /etc/init.d/pacemaker start crm_mon -Afr1As a result of running above command you should see output similar to one below:
Last updated: Wed Aug 20 15:47:47 2014 Stack: classic openais (with plugin) Current DC: node1 - partition with quorum Version: 1.1.10-14.el6_5.3-368c726 2 Nodes configured, 2 expected votes 4 Resources configured Online: [ node1 node2 ]Once corosync and pacemaker is running configure pacemaker to be able to manage PostgreSQL and needed shared IP addressees ( master only ):
property \ no-quorum-policy="ignore" \ stonith-enabled="false" \ crmd-transition-delay="0s" rsc_defaults \ resource-stickiness="INFINITY" \ migration-threshold="1" primitive ip-cluster ocf:heartbeat:IPaddr2 \ params \ ip="192.168.100.13" \ <<== modify this to be your shared cluster address (accessible by MP) nic="eth2" \ <<== modify this to be your interface where MP should be accessed cidr_netmask="24" \ <<== modify this if needed op start timeout="60s" interval="0s" on-fail="stop" \ op monitor timeout="60s" interval="10s" on-fail="restart" \ op stop timeout="60s" interval="0s" on-fail="block" primitive ip-rep ocf:heartbeat:IPaddr2 \ params \ ip="192.168.10.13" \ <<== modify this to be your shared address for PostgreSQL replication nic="eth1" \ <<== modify this to be interface PostgreSQL will use for replication cidr_netmask="24" \ <<== modify this if needed meta \ migration-threshold="0" \ op start timeout="60s" interval="0s" on-fail="restart" \ op monitor timeout="60s" interval="10s" on-fail="restart" \ op stop timeout="60s" interval="0s" on-fail="block" primitive pgsql ocf:heartbeat:pgsql \ params \ pgctl="/var/cfengine/bin/pg_ctl" \ psql="/var/cfengine/bin/psql" \ tmpdir="/var/cfengine/state/pg/tmp" \ pgdata="/var/cfengine/state/pg/data/" \ rep_mode="async" \ node_list="node1 node2" \ <<== modify this to point to host-names of MASTER and SLAVE respectivelly primary_conninfo_opt="keepalives_idle=60 keepalives_interval=5 keepalives_count=5" \ master_ip="192.168.10.13" \ <<== modify this to point to the shared address of PostgreSQL replication restart_on_promote="true" \ op start timeout="120s" interval="0s" on-fail="restart" \ op monitor timeout="60s" interval="4s" on-fail="restart" \ op monitor timeout="60s" interval="3s" on-fail="restart" role="Master" \ op promote timeout="120s" interval="0s" on-fail="restart" \ op demote timeout="120s" interval="0s" on-fail="stop" \ op stop timeout="120s" interval="0s" on-fail="block" \ op notify timeout="90s" interval="0s" ms pgsql-ms pgsql \ meta \ master-max="1" \ master-node-max="1" \ clone-max="2" \ clone-node-max="1" \ notify="true" group ip-group \ ip-cluster \ ip-rep colocation rsc_colocation-1 inf: ip-group pgsql-ms:Master order rsc_order-1 0: pgsql-ms:promote ip-group:start symmetrical=false order rsc_order-2 0: pgsql-ms:demote ip-group:stop symmetrical=falseTo apply above configuration create temporary file (*/tmp/cfengine.cib*) and run
crm configure < /tmp/cfengine.cib.Stop pacemaker and then corosync on both active and passive node.
NOTE: Don't worry if at this point you are seeing some pacemaker or corosync errors.
PostgreSQL configuration
Before starting this make sure that both corosync and pacemaker are not running.
- Install CFEngine hub package on both active and passive node.
- On active node bootstrap hub to itself to start acting as policy server (this step can be skipped if you are upgrading existing installation to High Availability).
- On passive node bootstrap it to active hub. While bootstrapping trust between both hubs will be established and keys will be exchanged.
After successful bootstrapping passive to active bootstrap passive to itself. From now on it will start operate as a hub so that it will be capable to collect reports and serve policy files. Please notice that while bootstrapping passive to itself you can see following message:
"R: This host assumes the role of policy server R: Updated local policy from policy server R: Failed to start the server R: Did not start the scheduler R: You are running a hard-coded failsafe. Please use the following command instead. "/var/cfengine/bin/cf-agent" -f /var/cfengine/inputs/update.cf 2014-09-29T17:36:24+0000 notice: Bootstrap to '10.100.100.116' completed successfully!"Configure PostgreSQL on active active node:
- Create two directories owned by PostgreSQL user: /var/cfengine/state/pg/data/pg_archive and /var/cfengine/state/pg/tmp
Modify postgresql.conf configuration file
echo "listen_addresses = '*' wal_level = hot_standby max_wal_senders=5 wal_keep_segments = 32 hot_standby = on restart_after_crash = off" >> /var/cfengine/state/pg/data/postgresql.confNOTE: In above configuration wal_keep_segments value specifies minimum number of segments (16 megabytes each) retained in PostgreSQL WAL logs directory in case a standby server needs to fetch them for streaming replication. It should be adjusted to number of clients handled by CFEngine hub and available disk space. Having installation with 1000 clients handled by CFEngine hub and assuming passive hub should be able to catch up with active one after 24 hours break, the value should be set close to 250 (4 GB of additional disk space).
Modify pg_hba.conf configuration file
echo "host replication all 192.168.10.10/32 trust host replication all 192.168.10.11/32 trust local replication all trust host replication all 127.0.0.1/32 trust host replication all ::1/128 trust " >> /var/cfengine/state/pg/data/pg_hba.confIMPORTANT: Above configuration allows accessing hub with cfpostgres user without any authentication from both cluster nodes. For security reasons we strongly advise to create replication user in PostgreSQL and protect access using password or certificate. What is more we advise using ssl-secured replication instead of described here unencrypted method.
Adding above changes needs PostgreSQL server to be restarted!
cd /tmp && su cfpostgres -c "/var/cfengine/bin/pg_ctl -w -D /var/cfengine/state/pg/data stop -m fast" cd /tmp && su cfpostgres -c "/var/cfengine/bin/pg_ctl -w -D /var/cfengine/state/pg/data -l /var/log/postgresql.log start"
Configure PostgreSQL on passive node:
- Remove PostgreSQL directory running following command
rm -rf /var/cfengine/state/pg/data/* - Do database backup running
su cfpostgres -c "cd /tmp && /var/cfengine/bin/pg_basebackup -h node1 -U cfpostgres -D /var/cfengine/state/pg/data -X stream -P Configure recovery.conf file indicating PostgreSQL running as hot-standby replica
echo "standby_mode = 'on' primary_conninfo = 'host=node1 port=5432 user=cfpostgres application_name=node2' " > /var/cfengine/state/pg/data/recovery.conf
NOTE: change host and application_name to point to host names of active and passive nodes respectively.
- Remove PostgreSQL directory running following command
Start PostgreSQL on passive hub using following command:
cd /tmp && su cfpostgres -c "/var/cfengine/bin/pg_ctl -w -D /var/cfengine/state/pg/data -l /var/log/postgresql.log start"
Verify PostgreSQL status on passive instance running echo "select pg_is_in_recovery();" | /var/cfengine/bin/psql cfdb.
Above should return t indicating that slave is working in recovery mode.
Verify if passive DB instance is connected to active running following command on active hub echo "select * from pg_stat_replication;" | /var/cfengine/bin/psql cfdb.
Above should return one entry indicating that host node1 is connected to database in streaming replication mode.
CFEngine configuration
Before starting this step make sure that PostgreSQL is running on both active and passive nodes and passive node is being replicated.
Create HA configuration file on both active and passive hubs like below:
echo "cmp_master: PRI cmp_slave: HS:async,HS:sync,HS:alone cmd: /usr/sbin/crm_attribute -l reboot -n pgsql-status -G -q" > /var/cfengine/ha.cfgCreate HA JSON configuration file as below:
echo "{ \"192.168.100.10\": { \"sha\": \"c14a17325b9a1bdb0417662806f579e4187247317a9e1739fce772992ee422f6\", \"internal_ip\": \"192.168.100.10\", \"tags\": [\"node1\"] }, \"192.168.100.11\": { \"sha\": \"b492eb4b59541c02a13bd52efe17c6a720e8a43b7c8f8803f3fc85dee7951e4f\", \"internal_ip\": \"192.168.100.11\", \"tags\": [\"node2\"] } }" > /var/cfengine/masterfiles/cfe_internal/ha/ha_info.jsonThe
internal_ipattribute is the IP address of the hub (the one you used to bootstrapped itself to) andshais the key of the hub. Theshakey can be found by runningcf-key -sthe on the respective hub and match that to theinternal_ip.Modify /var/cfengine/masterfiles/def.cf and enable HA by uncommenting
"enable_cfengine_enterprise_hub_ha" expression => "enterprise_edition";line (make sure to comment or remove line"enable_cfengine_enterprise_hub_ha" expression => "!any";).Run update.cf to make sure that new policy is copied from masterfiles to inputs
cf-agent -f update.cfon active first and then on passive.Start corosync and pacemaker on active node first. Make sure that PostgreSQL is running and managed by corosync/pacemaker. Verify the status using following commend
crm_mon -Afr1You should see something similar to one below:Last updated: Wed Aug 20 15:54:32 2014 Last change: Wed Aug 20 15:54:09 2014 via crm_attribute on node1 Stack: classic openais (with plugin) Current DC: node1 - partition WITHOUT quorum Version: 1.1.10-14.el6_5.3-368c726 2 Nodes configured, 2 expected votes 4 Resources configured Online: [ node1 ] OFFLINE: [ node2 ] Full list of resources: Master/Slave Set: pgsql-ms [pgsql] Stopped: [ node1 node2 ] Resource Group: ip-group ip-cluster (ocf::heartbeat:IPaddr2): Stopped ip-rep (ocf::heartbeat:IPaddr2): Stopped Node Attributes: * Node node1: + master-pgsql : -INFINITY + pgsql-data-status : LATEST + pgsql-status : STOP Migration summary: * Node node1: pgsql: migration-threshold=1 fail-count=2 last-failure='Wed Aug 20 15:54:12 2014' Failed actions: pgsql_monitor_4000 on node1 'not running' (7): call=28, status=complete, last-rc-change='Wed Aug 20 15:54:12 2014', queued=300ms, exec=1msBy default after starting corosync it will stop PostgreSQL as there is no connection with second node. pgsql-status should be STOP and PostgreSQL should not run. If this is the case repair PostgreSQL resource using
crm resource cleanup pgsql. After this runcrm_mon -Afr1again and wait until pgsql-status is reported as PRI.Start corosync on SLAVE node. After this second node should immediately be reported as passive and you should see output of
crm_mon -Afr1similar to one below:Last updated: Wed Aug 20 15:47:47 2014 Last change: Wed Aug 20 15:57:56 2014 via crm_attribute on node1 Stack: classic openais (with plugin) Current DC: node1 - partition with quorum Version: 1.1.10-14.el6_5.3-368c726 2 Nodes configured, 2 expected votes 4 Resources configured Online: [ node1 node2 ] Full list of resources: Master/Slave Set: pgsql-ms [pgsql] Masters: [ node1 ] Slaves: [ node2 ] Resource Group: ip-group ip-cluster (ocf::heartbeat:IPaddr2): Started node1 ip-rep (ocf::heartbeat:IPaddr2): Started node1 Node Attributes: * Node node1: + master-pgsql : 1000 + pgsql-data-status : LATEST + pgsql-master-baseline : 0000000006000090 + pgsql-status : PRI * Node node2: + master-pgsql : 1000 + pgsql-data-status : STREAMING|ASYNC + pgsql-status : HS:alone + pgsql-xlog-loc : 00000000060000F8 Migration summary: * Node node1: * Node node2:IMPORTANT: Please make sure that pgsql-status for the active node is reported as PRI and passive as HS:alone or HS:async.
Enjoy your working CFEngine High Availability setup!