Installation guide
Overview
This tutorial is describing the installation steps of the CFEngine High availability feature. It is suitable for both upgrading existing CFEngine installations to HA and for installing HA from scratch. Before starting installation we strongly recommend reading the CFEngine High availability overview.
Installation procedure
As with most High availability systems, setting it up requires carefully following a series of steps with dependencies on network components. The setup can therefore be error-prone, so if you are a CFEngine Enterprise customer we recommend that you contact support for assistance if you do not feel 100% comfortable of doing this on your own.
Please also make sure you have a valid license for the passive hub so that it will be able to handle all your CFEngine clients in case of failover.
Hardware configuration and OS pre-configuration steps
- CFEngine 3.15.3 (or later) hub package for RHEL7 or CentOS7.
- We recommend selecting dedicated interface used for PostgreSQL replication and optionally one for heartbeat.
- We recommend having one shared IP address assigned for interface where MP is accessible (optionally) and one where PostgreSQL replication is configured (mandatory).
- Both active and passive hub machines must be configured so that host names are different.
- Basic hostname resolution works (hub names can be placed in /etc/hosts or DNS configured).
Example configuration used in this tutorial
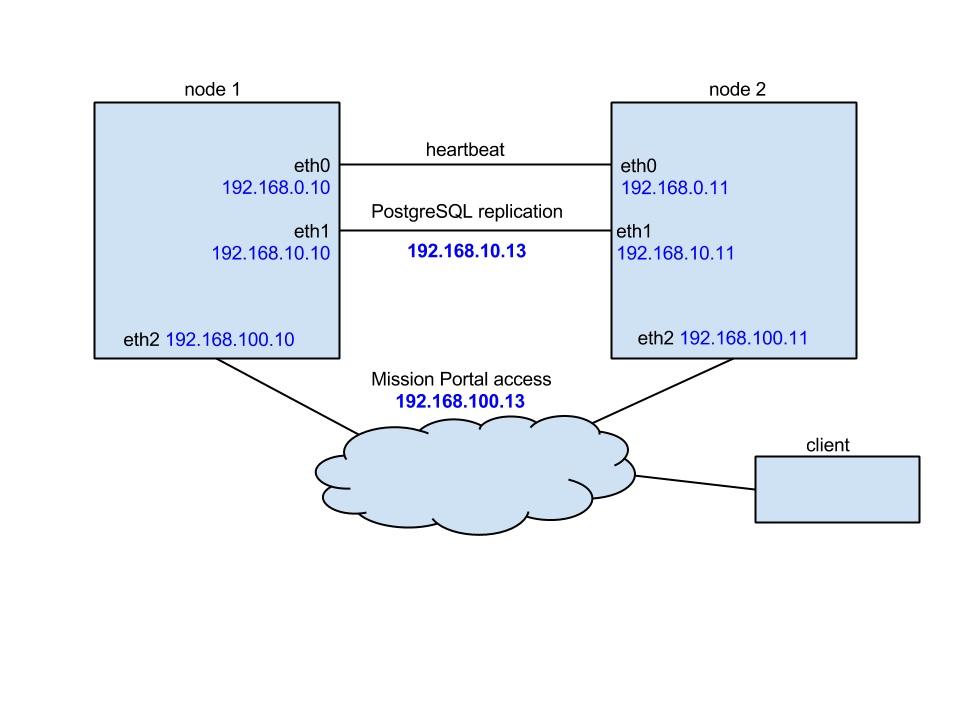
In this tutorial we use the following network configuration:
- Two nodes, one acting as active (node1) and one acting as passive (node2).
- Optionally a third node (node3) used as a database backup for offsite replication.
- Each node having three NICs so that eth0 is used for the heartbeat, eth1 is used for PostgreSQL replication and eth2 is used for MP and bootstrapping clients.
- IP addresses configured as follows:
| Node | eth0 | eth1 | eth2 |
|---|---|---|---|
| node1 | 192.168.0.10 | 192.168.10.10 | 192.168.100.10 |
| node2 | 192.168.0.11 | 192.168.10.11 | 192.168.100.11 |
| node3 (optional) | --- | 192.168.10.12 | 192.168.100.12 |
| cluster shared | --- | --- | 192.168.100.100 |
Detailed network configuration is shown on the picture below:
Install cluster management tools
On both nodes:
yum -y install pcs pacemaker cman fence-agents
In order to operate cluster, proper fencing must be configured but description how to fence cluster and what mechanism use is out of the scope of this document. For reference please use the Red Hat HA fencing guide.
IMPORTANT: please carefully follow the indicators describing if the given step should be performed on the active (node1), the passive (node2) or both nodes.
Make sure that the hostnames of all nodes nodes are node1 and node2 respectively. Running the command
uname -n | tr '[A-Z]' '[a-z]'should return the correct node name. Make sure that the DNS or entries in /etc/hosts are updated so that hosts can be accessed using their host names.In order to use pcs to manage the cluster, create the hacluster user designated to manage the cluster with
passwd haclusteron both nodes.Make sure that pcsd demon is started and configure both nodes so that it will be enabled to boot on startup on both nodes.
codeservice pcsd start chkconfig pcsd onAuthenticate hacluster user for each node of the cluster. Run the command below on the node1:
codepcs cluster auth node1 node2 -u haclusterAfter entering password, you should see a message similar to one below:
codenode1: Authorized node2: AuthorizedCreate the cluster by running the following command on the node1:
codepcs cluster setup --name cfcluster node1 node2This will create the cluster
cfclusterconsisting of node1 and node2.Give the cluster time to settle (cca 1 minute) and then start the cluster by running the following command on the node1:
codepcs cluster start --allThis will start the cluster and all the necessary deamons on both nodes.
At this point the cluster should be up and running. Running
pcs statusshould print something similar to the output below.codeCluster name: cfcluster WARNING: no stonith devices and stonith-enabled is not false Stack: cman Current DC: node2 (version 1.1.18-3.el6-bfe4e80420) - partition with quorum Last updated: Wed Oct 17 12:25:42 2018 Last change: Wed Oct 17 12:24:52 2018 by root via crmd on node2 2 nodes configured 0 resources configured Online: [ node1 node2 ] No resources Daemon Status: cman: active/disabled corosync: active/disabled pacemaker: active/disabled pcsd: active/enabledIf you are setting up just a testing environment without fencing, you should disable it now (**on the node1**):
codepcs property set stonith-enabled=false pcs property set no-quorum-policy=ignoreBefore the PostgreSQL replication is setup, we need to set up a floating IP address that will always point to the active node and configure some basic resource parameters (**on the node1**):
codepcs resource defaults resource-stickiness="INFINITY" pcs resource defaults migration-threshold="1" pcs resource create cfvirtip IPaddr2 ip=192.168.100.100 cidr_netmask=24 --group cfengine pcs cluster enable --allVerify that the cfvirtip resource is properly configured and running.
codepcs statusshould give something like this:
codeCluster name: cfcluster Last updated: Tue Jul 7 09:29:10 2015 Last change: Fri Jul 3 08:41:24 2015 Stack: cman Current DC: node1 - partition with quorum Version: 1.1.11-97629de 2 Nodes configured 1 Resources configured Online: [ node1 node2 ] Full list of resources: Resource Group: cfengine cfvirtip (ocf::heartbeat:IPaddr2): Started node1
PostgreSQL configuration
- Install the CFEngine hub package on both node1 and node2.
Make sure CFEngine is not running (**on both node1 and node2**):
codeservice cfengine3 stopConfigure PostgreSQL on node1:
Create two special directories owned by the cfpostgres user:
codemkdir -p /var/cfengine/state/pg/{data/pg_arch,tmp} chown -R cfpostgres:cfpostgres /var/cfengine/state/pg/{data/pg_arch,tmp}Modify the /var/cfengine/state/pg/data/postgresql.conf configuration file to set the following options accordingly (**uncomment the lines if they are commented out**):
codelisten_addresses = '*' wal_level = replica max_wal_senders = 5 wal_keep_segments = 16 hot_standby = on restart_after_crash = off archive_mode = on archive_command = 'cp %p /var/cfengine/state/pg/data/pg_arch/%f'Modify the pg_hba.conf configuration file to enable access to PostgreSQL for replication between the nodes (note that the second pair of IP addresses, not the heartbeat pair, is used here):
codeecho "host replication all 192.168.100.10/32 trust" >> /var/cfengine/state/pg/data/pg_hba.conf echo "host replication all 192.168.100.11/32 trust" >> /var/cfengine/state/pg/data/pg_hba.confIMPORTANT: The above configuration allows accessing PostgreSQL without any authentication from both cluster nodes. For security reasons we strongly advise to create a replication user in PostgreSQL and protect access using a password or certificate. Furthermore, we advise using ssl-secured replication instead of the unencrypted method described here if the hubs are in an untrusted network.
Do an initial sync of PostgreSQL:
Start PostgreSQL on node1:
codepushd /tmp; su cfpostgres -c "/var/cfengine/bin/pg_ctl -w -D /var/cfengine/state/pg/data -l /var/log/postgresql.log start"; popdOn node2, initialize PostgreSQL from node1 (again using the second IP, not the heartbeat IP):
coderm -rf /var/cfengine/state/pg/data/* pushd /tmp; su cfpostgres -c "/var/cfengine/bin/pg_basebackup -h 192.168.10.10 -U cfpostgres -D /var/cfengine/state/pg/data -X stream -P"; popdOn node2, create the standby.conf file and configure PostgreSQL to run as a hot-standby replica:
codecat <<EOF > /var/cfengine/state/pg/data/standby.conf #192.168.100.100 is the shared over cluster IP address of active/master cluster node primary_conninfo = 'host=192.168.100.100 port=5432 user=cfpostgres application_name=node2' restore_command = 'cp /var/cfengine/state/pg/pg_arch/%f %p' EOF chown --reference /var/cfengine/state/pg/data/postgresql.conf /var/cfengine/state/pg/data/standby.conf echo "include 'standby.conf'" >> /var/cfengine/state/pg/data/postgresql.conf touch /var/cfengine/state/pg/data/standby.signal
Start PostgreSQL on the node2 by running the following command:
codepushd /tmp; su cfpostgres -c "/var/cfengine/bin/pg_ctl -D /var/cfengine/state/pg/data -l /var/log/postgresql.log start"; popdCheck that PostgreSQL replication is setup and working properly:
The node2 should report it is in the recovery mode:
code/var/cfengine/bin/psql -x cfdb -c "SELECT pg_is_in_recovery();"should return:
code-[ RECORD 1 ]-----+-- pg_is_in_recovery | tThe node1 should report it is replicating to node2:
code/var/cfengine/bin/psql -x cfdb -c "SELECT * FROM pg_stat_replication;"should return something like this:
code-[ RECORD 1 ]----+------------------------------ pid | 11401 usesysid | 10 usename | cfpostgres application_name | node2 client_addr | 192.168.100.11 client_hostname | node2-pg client_port | 33958 backend_start | 2018-10-16 14:19:04.226773+00 backend_xmin | state | streaming sent_lsn | 0/61E2C88 write_lsn | 0/61E2C88 flush_lsn | 0/61E2C88 replay_lsn | 0/61E2C88 write_lag | flush_lag | replay_lag | sync_priority | 0 sync_state | async
Stop PostgreSQL on both nodes:
codepushd /tmp; su cfpostgres -c "/var/cfengine/bin/pg_ctl -D /var/cfengine/state/pg/data -l /var/log/postgresql.log stop"; popdRemove the hot-standby configuration on node2. It will be handled by the cluster resource and the resource agent.
coderm -f /var/cfengine/state/pg/data/standby.signal rm -f /var/cfengine/state/pg/data/standby.conf sed -i "/standby\.conf/d" /var/cfengine/state/pg/data/postgresql.conf
Cluster resource configuration
Download the PostgreSQL resource agent supporting the CFEngine HA setup on both nodes.
codewget https://raw.githubusercontent.com/cfengine/core/master/contrib/pgsql_RA /bin/cp pgsql_RA /usr/lib/ocf/resource.d/heartbeat/pgsql chown --reference /usr/lib/ocf/resource.d/heartbeat/{IPaddr2,pgsql} chmod --reference /usr/lib/ocf/resource.d/heartbeat/{IPaddr2,pgsql}Create the PostgreSQL resource (**on node1**).
codepcs resource create cfpgsql pgsql \ pgctl="/var/cfengine/bin/pg_ctl" \ psql="/var/cfengine/bin/psql" \ pgdata="/var/cfengine/state/pg/data" \ pgdb="cfdb" pgdba="cfpostgres" repuser="cfpostgres" \ tmpdir="/var/cfengine/state/pg/tmp" \ rep_mode="async" node_list="node1 node2" \ primary_conninfo_opt="keepalives_idle=60 keepalives_interval=5 keepalives_count=5" \ master_ip="192.168.100.100" restart_on_promote="true" \ logfile="/var/log/postgresql.log" \ config="/var/cfengine/state/pg/data/postgresql.conf" \ check_wal_receiver=true restore_command="cp /var/cfengine/state/pg/data/pg_arch/%f %p" \ op monitor timeout="60s" interval="3s" on-fail="restart" role="Master" \ op monitor timeout="60s" interval="4s" on-fail="restart" --disableConfigure PostgreSQL to work in Master/Slave (active/standby) mode (**on node1**).
codepcs resource master mscfpgsql cfpgsql master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 notify=trueTie the previously configured shared IP address and PostgreSQL cluster resources to make sure both will always run on the same host and add migration rules to make sure that resources will be started and stopped in the correct order (**on node1**).
codepcs constraint colocation add cfengine with Master mscfpgsql INFINITY pcs constraint order promote mscfpgsql then start cfengine symmetrical=false score=INFINITY pcs constraint order demote mscfpgsql then stop cfengine symmetrical=false score=0Enable and start the new resource now that it is fully configured (**on node1**).
codepcs resource enable mscfpgsql --wait=30Verify that the constraints configuration is correct.
codepcs constraintshould give:
codeLocation Constraints: Resource: mscfpgsql Enabled on: node1 (score:INFINITY) (role: Master) Ordering Constraints: promote mscfpgsql then start cfengine (score:INFINITY) (non-symmetrical) demote mscfpgsql then stop cfengine (score:0) (non-symmetrical) Colocation Constraints: cfengine with mscfpgsql (score:INFINITY) (rsc-role:Started) (with-rsc-role:Master)Verify that the cluster is now fully setup and running.
codecrm_mon -Afr1should give something like:
codeStack: cman Current DC: node1 (version 1.1.18-3.el6-bfe4e80420) - partition with quorum Last updated: Tue Oct 16 14:19:37 2018 Last change: Tue Oct 16 14:19:04 2018 by root via crm_attribute on node1 2 nodes configured 3 resources configured Online: [ node1 node2 ] Full list of resources: Resource Group: cfengine cfvirtip (ocf::heartbeat:IPaddr2): Started node1 Master/Slave Set: mscfpgsql [cfpgsql] Masters: [ node1 ] Slaves: [ node2 ] Node Attributes: * Node node1: + cfpgsql-data-status : LATEST + cfpgsql-master-baseline : 0000000004000098 + cfpgsql-receiver-status : normal (master) + cfpgsql-status : PRI + master-cfpgsql : 1000 * Node node2: + cfpgsql-data-status : STREAMING|ASYNC + cfpgsql-receiver-status : normal + cfpgsql-status : HS:async + master-cfpgsql : 100IMPORTANT: Please make sure that there's one Master node and one Slave node and that the cfpgsql-status for the active node is reported as PRI and passive as HS:async or HS:alone.
CFEngine configuration
Create the HA configuration file on both nodes.
codecat <<EOF > /var/cfengine/ha.cfg cmp_master: PRI cmp_slave: HS:async,HS:sync,HS:alone cmd: /usr/sbin/crm_attribute -l reboot -n cfpgsql-status -G -q EOFMask the cf-postgres.service and make sure it is not required by the cf-hub.service on both nodes (PostgreSQL is managed by the cluster resource, not by the service).
codesed -ri s/Requires/Wants/ /usr/lib/systemd/system/cf-hub.service systemctl daemon-reload systemctl mask cf-postgres.serviceBootstrap the nodes.
Bootstrap the node1 to itself and make sure the initial policy (
promises.cf) evaluation is skipped:codecf-agent --bootstrap 192.168.100.10 --skip-bootstrap-policy-runBootstrap the node2 to node1 (to establish trust) and then to itself, again skipping the initial policy evaluation:
codecf-agent --bootstrap 192.168.100.10 --skip-bootstrap-policy-run cf-agent --bootstrap 192.168.100.11 --skip-bootstrap-policy-runStop CFEngine on both nodes.
codeservice cfengine3 stopCreate the HA JSON configuration file on both nodes.
codecat <<EOF > /var/cfengine/masterfiles/cfe_internal/enterprise/ha/ha_info.json { "192.168.100.10": { "sha": "@NODE1_PKSHA@", "internal_ip": "192.168.100.10" }, "192.168.100.11": { "sha": "@NODE2_PKSHA@", "internal_ip": "192.168.100.11" } } EOFThe
@NODE1_PKSHA@and@NODE2_PKSHA@strings are placeholders for the host key hashes of the nodes. Replace the placeholders with real values obtained by (on any node):codecf-key -sIMPORTANT: Copy over only the hashes, without the
SHA=prefix.On both nodes, add the following class definition to the /var/cfengine/masterfiles/def.json file to enable HA:
code{ "classes": { "enable_cfengine_enterprise_hub_ha": [ "any::" ] } }On both nodes, run
cf-agent -Kf update.cfto make sure that the new policy is copied from masterfiles to inputs.Start CFEngine on both nodes.
codeservice cfengine3 startCheck that the CFEngine HA setup is working by logging in to the Mission Portal at the https://192.168.100.100 address in your browser. Note that it takes up to 15 minutes for everything to settle and the
OKHA status being reported in the Mission Portal's header.
Configuring 3rd node as disaster-recovery or database backup (optional)
Install the CFEngine hub package on the node which will be used as disaster-recovery or database backup node (node3).
Bootstrap the disaster-recovery node to active node first (establish trust between hubs) and then bootstrap it to itself. At this point hub will be capable of collecting reports and serve policy.
Stop cf-execd and cf-hub processes.
Make sure that PostgreSQL configuration allows database replication connection from 3rd node (see PostgreSQL configuration section, point 5.3 for more details).
Repeat steps 4 - 6 from PostgreSQL configuration to enable and verify database replication connection from the node3. Make sure that both the node2 and node3 are connected to active database node and streaming replication is in progress.
Running the following command on node1:
code/var/cfengine/bin/psql cfdb -c "SELECT * FROM pg_stat_replication;"Should give: ``` pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | state | sent_location | write_location | flush_location | replay_location | sync_priority | sync_state ------+----------+------------+------------------+----------------+-----------------+-------------+-------------------------------+-----------+---------------+----------------+----------------+-----------------+---------------+------------ 9252 | 10 | cfpostgres | node2 | 192.168.100.11 | | 58919 | 2015-08-24 07:14:45.925341+00 | streaming | 0/2A7034D0 | 0/2A7034D0 | 0/2A7034D0 | 0/2A7034D0 | 0 | async 9276 | 10 | cfpostgres | node3 | 192.168.100.12 | | 52202 | 2015-08-24 07:14:46.038676+00 | streaming | 0/2A7034D0 | 0/2A7034D0 | 0/2A7034D0 | 0/2A7034D0 | 0 | async
(2 rows) ```
Modify HA JSON configuration file to contain information about the node3 (see CFEngine configuration, step 2). You should have configuration similar to one below:
code[root@node3 masterfiles]# cat /var/cfengine/masterfiles/cfe_internal/enterprise/ha/ha_info.json { "192.168.100.10": { "sha": "b1463b08a89de98793d45a52da63d3f100247623ea5e7ad5688b9d0b8104383f", "internal_ip": "192.168.100.10", "is_in_cluster" : true, }, "192.168.100.11": { "sha": "b13db51615afa409a22506e2b98006793c1b0a436b601b094be4ee4b32b321d5", "internal_ip": "192.168.100.11", }, "192.168.100.12": { "sha": "98f14786389b2fe5a93dc3ef4c3c973ef7832279aa925df324f40697b332614c", "internal_ip": "192.168.100.12", "is_in_cluster" : false, } }Please note that
is_in_clusterparameter is optional for the 2 nodes in the HA cluster and by default is set to true. For the 3-node setup, the node3, which is not part of the cluster, MUST be marked with"is_in_cluster" : falseconfiguration parameter.Start the cf-execd process (don't start cf-hub process as this is not needed while manual failover to the node3 is not performed). Please also note that during normal operations the cf-hub process should not be running on the node3.
Manual failover to disaster-recovery node
Before starting manual failover process make sure both active and passive nodes are not running.
Verify that PostgreSQL is running on 3rd node and data replication from active node is not in progress. If database is actively replicating data with active cluster node make sure that this process will be finished and no new data will be stored in active database instance.
After verifying that replication is finished and data is synchronized between active database node and replica node (or once node1 and node2 are both down) promote PostgreSQL to exit recovery and begin read-write operations
cd /tmp && su cfpostgres -c "/var/cfengine/bin/pg_ctl -c -w -D /var/cfengine/state/pg/data -l /var/log/postgresql.log promote".In order to make failover process as easy as possible there is
"failover_to_replication_node_enabled"class defined both in /var/cfengine/masterfiles/controls/VERSION/def.cf and /var/cfengine/masterfiles/controls/VERSION/update_def.cf. In order to stat collecting reports and serving policy from 3rd node uncomment the line defining mentioned class.
IMPORTANT: Please note that as long as any of the active or passive cluster nodes is accessible by client to be contacted, failover to 3rd node is not possible. If the active or passive node is running and failover to 3rd node is required make sure to disable network interfaces where clients are bootstrapped to so that clients won't be able to access any other node than disaster-recovery.
Troubleshooting
If either the IPaddr2 or pgslq resource is not running, try to enable it first with
pcs cluster enable --all. If this is not strting the resources, you can try to run them in debug mode with this commandpcs resource debug-start <resource-name>. The latter command should print diagnostics messages on why resources are not started.If
crm_mon -Afr1is printing errors similar to the belowcode[root@node1]# pcs status Cluster name: cfcluster Last updated: Tue Jul 7 11:27:23 2015 Last change: Tue Jul 7 11:02:40 2015 Stack: cman Current DC: node1 - partition with quorum Version: 1.1.11-97629de 2 Nodes configured 3 Resources configured Online: [ node1 ] OFFLINE: [ node2 ] Full list of resources: Resource Group: cfengine cfvirtip (ocf::heartbeat:IPaddr2): Started node1 Master/Slave Set: mscfpgsql [cfpgsql] Stopped: [ node1 node2 ] Failed actions: cfpgsql_start_0 on node1 'unknown error' (1): call=13, status=complete, last-rc-change='Tue Jul 7 11:25:32 2015', queued=1ms, exec=137msyou can try to clear the errors by running
pcs resource cleanup <resource-name>. This should clean errors for the appropriate resource and make the cluster restart it.code[root@node1 vagrant]# pcs resource cleanup cfpgsql Resource: cfpgsql successfully cleaned up [root@node1 vagrant]# pcs status Cluster name: cfcluster Last updated: Tue Jul 7 11:29:36 2015 Last change: Tue Jul 7 11:29:08 2015 Stack: cman Current DC: node1 - partition with quorum Version: 1.1.11-97629de 2 Nodes configured 3 Resources configured Online: [ node1 ] OFFLINE: [ node2 ] Full list of resources: Resource Group: cfengine cfvirtip (ocf::heartbeat:IPaddr2): Started node1 Master/Slave Set: mscfpgsql [cfpgsql] Masters: [ node1 ] Stopped: [ node2 ]After cluster crash make sure to always start the node that should be active first, and then the one that should be passive. If the cluster is not running on the given node after restart you can enable it by running the following command:
code[root@node2]# pcs cluster start Starting Cluster...
 Chat
Chat Ask a question on Github
Ask a question on Github Mailing list
Mailing list