Hosts and Health
Host Compliance
CFEngine collects data on promise compliance. Each host is in one of two groups: out of compliance or fully compliant.
- A host is considered out of compliance if less than 100% of its promises were kept.
- A host is considered fully compliant if 100% of its promises were kept.
You can look at a specific sub-set of your hosts by selecting a category from the menu on the left.
Host Info
Here you will find extensive information on single hosts that CFEngine detects automatically in your environment. Since this is data gathered per host, you need to select a single host from the menu on the left first.
Host Health
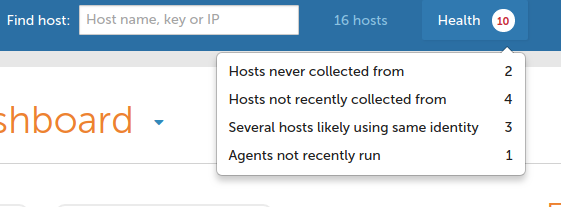
You can get quick access to the health of hosts, including direct links to reports, from the Health drop down at the top of every Enterprise UI screen. Hosts are listed as unhealthy if:
- the hub was not able to connect to and collect data from the host within a set time interval (unreachable host). The time interval can be set in the Mission Portal settings.
- the policy did not get executed for the last three runs. This could be caused by
cf-execdnot running on the host (scheduling deviation) or an error in policy that stops its execution. The hub is still able to contact the host, but it will return stale data because of this deviation. - two or more hosts use the same key. This is detected by "reporting cookies", randomized tokens generated every report collection. If the client presents a mismatching cookie (compared to last collection) a collision is detected. The number of collisions (per hostkey) that cause the unhealthy status is configurable in settings.
- reports have recently been collected, but cf-agent has not recently run. "Recently" is defined by the configured run-interval of their cf-agent.
These categories are non-overlapping, meaning a host will only appear in one category at at time even if conditions satisfying multiple categories might be present. This makes reports simpler to read, and makes it easier to detect and fix the root cause of the issue. As one issue is resolved the host might then move to another category. In either situation the data from that host will be from old runs and probably not reflect the current state of that host.