By scalability we mean the intrinsic capacity of a system to handle growth. Growth in a system can occur in three ways: by the volume of input the system must handle, or in the total size of its infrastructure, and by the complexity of the processes within it.
For a system to be called scalable, growth should proceed unhindered, i.e. the size and volume of processing may expand without significantly affecting the average service level per node.
Although most of us have an intuitive notion of what scalability means, a full understanding of it is a very complex issue, mainly because there are so many factors to take into account. One factor that is often forgotten in considering scalability, is the human ability to comprehend the system as it grows. Limitations of comprehension often lead to over-simplification and lowest-common-denominator standardization. This ultimately causes systems to fail due to an information deficit.
| CFEngine is a decentralized (or federated) agent-based system, with no single point of failure. It uses integrated Knowledge Management to present comprehensible views of how infrastructure complies with user intentions. |
In this Special Topics Guide, we take a simple approach to gauging the scalability of CFEngine, considering the worst case scalability of the software as a management system for typical environments and network models.
CFEngine's scalability is not only a function of the CFEngine software, but also of the environment in which it operates and the choices that are made. Some relevant environmental factors include:
For managers, there are several challenges to scaling that go beyond the infrastructure:
CFEngine does all processing of configuration policy at the destination node (i.e. on the affected system). There is no centralization of computation. CFEngine Nova adds fault-tolerant multi-node orchestration, in which any node's state can be made available to other nodes on request.
In general, reliance on common or centralized information will limit the inherent scalability of the system. However, through opportunistic use of caching, CFEngine is able to avoid single points of reliance. CFEngine's asynchronous promise model makes the impact of resource sharing less significant.
CFEngine's scaling behaviour follows an `astronomical' hierarchy of scales. Our product range have been chosen to model different issues of scale that occur in systems as they grow from tens to tens of thousands of machines. As indicated above, dealing with scale is not just about machine capacity, but also about knowledge management and comprehension.
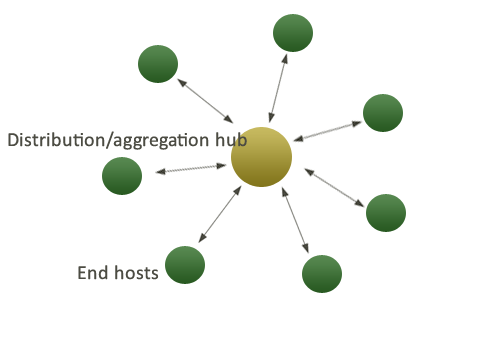
An Enterprise installation is designed around a single star configuration (like a solar system) in which the hub machine is the star and the managed entities are the planets. Special planets can have their own satellites (customized environments within the single point of control), so this model does not imply complete uniformity.
Future releases will be designed around multiple star configurations and for cases where it is desirable to maintain several points of control or independently managed entities. This is also called a federation of star networks. The reason for choosing this kind of architecture may or may not have to do with service capacity (i.e. for coping with a large number of systems): sometimes knowledge management and responsibilities scale better with federation.
This section proposes a simple method for evaluating capacity and scalability at a site. You will need some numbers in order to do some simple calculations.
You will be able to use these numbers in the next chapter to work out how far a simple star network configuration (Nova starburst) will go in supporting requirements. An environment that consists of multiple environments, or very large size will have to be handled as a constellation configuration.
Several architectural principles aid the ability to scale to large size:
The picture of a federated architecture is that of a number of smaller star networks loosely rather than tightly integrated together. This loose coupling avoids rigidity that can cause cascade failure.
This schematic architecture does not answer where these centres will be located however. Will the division into local centres be based on geography, departmental lines, or some other virtual view of the organization?
| It does not matter from an architectural point of view what criteria are used for dividing up an organization. The main criteria is the environment itself. If we think in terms of promises for a moment, a strong group culture forms when members of a community make a lot of promises to one another. Organizational entities are therefore clusters of promises. This might or might not coincide with naming of institutional entities. |
It is easy to understand the reason for a promise-oriented approach to scalability. Clusters of promises are also clusters where communication is likely to be required and take place. Since scalability is enhanced by limiting the amount and scope of communication, the clusters of promises mark out the areas (sub-networks, if you like) where communication is necessary. This makes for a natural encapsulation of policy issues.
Part of the challenge of scale is comprehension. If every computer is identical, this is no problem, but when there is real growth in complexity scale can lead to a case of information and comprehension overload. Checking that growth of complexity requires some user discipline.
What if you have written down 250,000 promises to keep? How can you manage that? Here are some tips:
If you are migrating from CFEngine 2, then many of your separate promises can be turned into a single promise by using lists and other patterns. This will drastically improve the modelling capabilities and reduce the complexity of the policy.
The criterion for dividing up the organization is to make the entities as autonomous as possible, i.e. with as few dependencies or communication requirements as possible. The configurations for each autonomous entity should be kept and managed locally by those entities, and not mixed together. Centralization is the enemy of scaling.
bundle agent service_emailnot by configuration file:
bundle agent etc_conf_postfixEven a non-expert should be able to see what these bundles are for, even if they don't understand their detailed content.
In writing policy, the thing most often forgotten by technicians is explaining why decisions have been made.
perms => m("0600"), try writing
something that allows readers to understand the reason for the intention: perms =>write standard_permissions.
comment => "This file needs to be writable by the web server
else application XYZ breaks"
instead of
comment => "Set permissions on the temp directory"
"group" slist => {
classify("a.domain.com"),
classify("b.domain.com"),
.....4000x...
};
This is neat, and easy to read but it requires CFEngine to process
a list linearly, which becomes increasingly inefficient and can take several
seconds if a list contains thousands of hosts. Some improvement can be obtained
by converting the domain strings manually:
"group" slist => {
"a_domain_com",
"b_domain_com",
.....4000x...
};
However, the linear scaling is still present.
In this case, it is inefficient to process the list in memory, because we only need one out of thousands of the entries, thus it makes sense to prune the list in advance.
To handle this, we can create a flat file of data in the format
"hostname:group" using the builtin function getfields() to read
one line from the file.
vars:
"match_name" int => getfields("a.domain.com:.*","/my/file",":","group_data");
classes:
"$(group_data[2])" expression => isgreaterthan("$(match_name)","0");;
This assumes, of course, that each host is in one and only one class context. The saving in processing is large, however, as it can be carried out directly in the input buffer. Only one out of thousands of lines thus needs to be processes. Although the scaling is still linear in search, the allocation and read processes are heavily optimized by block device reading and much lower overhead.
A module could also be used to the same effect to define the appropriate class context.
As of version 3.4.0 of the CFEngine core, persistent classes can be used to construct a simple time-saving caching of classes that depend on very large amounts of data. This feature can be used to avoid recomputing expensive classes calculations on each invocation. If a class discovered is essentially constant or only slowly varying (like a hostname or alias from a non-standard naming facility)
For example, to create a conditional inclusion of costly class definitions, put them into a separate bundle in a file classes.cf.
# promises.cf
body common control
{
cached_classes::
bundlesequence => { "test" };
!cached_classes::
bundlesequence => { "setclasses", "test" };
!cached_classes::
inputs => { "classes.cf" };
}
bundle agent test
{
reports:
!my_cached_class::
"no cached class";
my_cached_class::
"cached class defined";
}
Then create classes.cf
# classes.cf
bundle common setclasses
{
classes:
"cached_classes" # timer flag
expression => "any",
persistence => "480";
"my_cached_class"
or => { ...long list or heavy function... } ,
persistence => "480";
}
In a large system it is natural to expect a large number of promises. This makes the location of a specific promise difficult. The Copernicus Knowledge Map is a key strategy for locating promises.
files: in a bundle. However,
splitting up type-sections makes human readability harder.
Connecting to a CFEngine server process is one of the most time consuming activities in centralized updating. Every bidirectional query that has to be made adds latency and processing time the limits scalability. The connection time and data transfer size during checking for updates can be minimized by making use of the cf_promises_validated cache file on the server. This file summarizes whether it is necessary to search for file updates (a search that can take a significant number of seconds per client). Since most checks do not result in a required update, this cache file can save a large amount of network traffic.
files:
"$(inputs_dir)/cf_promises_validated"
comment => "Check whether new policy update to reduce the distributed load",
handle => "check_valid_update",
copy_from => u_dcp("$(master_location)/cf_promises_validated","$(sys.policy_hub)"),
action => u_immediate,
classes => u_if_repaired("validated_updates_ready");
am_policy_hub|validated_updates_ready::
"$(inputs_dir)"
comment => "Copy policy updates from master source on policy server if a new validation was acquired",
handle => "update_files_inputs_dir",
copy_from => u_rcp("$(master_location)","$(sys.policy_hub)"),
depth_search => u_recurse("inf"),
file_select => u_input_files,
depends_on => { "grant_access_policy", "check_valid_update" },
action => u_immediate,
classes => u_if_repaired("update_report");
Modelling environments with classes is a powerful strategy for knowledge management, and is therefore encouraged.
The Copernicus Knowledge Map is an integral part of the commercial CFEngine products. It is also a feature that is developing rapidly as part of the CFEngine commitment to research and development. It forms a browsable `mental model' of relationships between promises, goals and documents that describe them (including the manuals and other documentation sources). The map provides you with an overview of how parts of your policy relate to one another, and to other high level parts of your environment.
Use the knowledge map to:
CFEngine uses MongoDB as its repository of information for each Nova/Enterprise hub. The performance of a hub depends on the combination of hardware and software. The CFEngine hub falls under the category or role of database server, and this requires fairly specific optimizations. For example, NUMA architecture processing is known to lead to severe processing bottlenecks on database servers, and so NUMA kernel modules should be switched off. Below are some of the optimizations that should be looked into for the CFEngine hubs.
Although CFEngine communicates with the Mongo database over a local socket, it still uses TCP as its connection protocol and is therefore subject to kernel optimizations.
Every write and read connection to the Mongo database makes a kernel TCP connection. With the extreme density of connections, this is somewhat like a high volume webserver. The standard `play safe' kernel settings are too conservative for this kind of performance. The main bottleneck eventually becomes the FIN_WAIT timeout, which leaves file descriptors occupied and non-recyclable for too long. We recommend reducing this waiting time to free up descriptors faster:
echo "1024 61000" > /proc/sys/net/ipv4/ip_local_port_range echo "5" > /proc/sys/net/ipv4/tcp_fin_timeoutThis will clear old connections faster, allowing new ones be created and old threads to terminate faster.
Some points to consider when scaling the MongoDB:
cf-hub. The incices are
checked every six hours.
However, if the database schema changes, which may happen during upgrades of CFEngine Nova, the indices may have been changed as well. In large-scale environment we may not have time to wait up to six hours for the indices to get repaired, so this can be done manually by running the following command on the hub.
/var/cfengine/bin/cf-hub --index
Please make sure cf-hub is not running in the background while
indices are being created, as this may slow the system down
considerably under high load.
To make sure that server connection performance does not suffer as a result of aggressive database writing, we can lower the priority of the MongoDB process
ionice -c2 -n0 /var/cfengine/bin/mongodor, using the PID
ionice -c2 -n0 -p PID
Some users report that using this approach is sufficient:
numactl --interleave=all /var/cfengine/bin/mongod # (other args)
echo 0 > /proc/sys/vm/zone_reclaim_mode
However, in our experience, only removing the kernel modules
supporting NUMA and rebooting the kernel will solve the NUMA contention issue.
Setting:
numa=offin the kernel boot parameters, e.g. in grub.conf:
# grub.conf generated by anaconda
#
# Note that you do not have to rerun grub after making changes to this file
# NOTICE: You do not have a /boot partition. This means that
# all kernel and initrd paths are relative to /, eg.
# root (hd0,0)
# kernel /boot/vmlinuz-version ro root=/dev/sda1
# initrd /boot/initrd-version.img
#boot=/dev/sda
default=0
timeout=5
splashimage=(hd0,0)/boot/grub/splash.xpm.gz
hiddenmenu
title MY Linux Server (2.6.32-100.26.2.el5uek)
root (hd0,0)
kernel /boot/vmlinuz-2.6.32-100.26.2.el5 ro root=/dev/sda1 rhgb quiet numa=off
initrd /boot/initrd-2.6.32-100.26.2.el5.img
|
splaytime on the client nodes will help to spread out
the incoming connections over the update interval of the hub. The hub
defaults to 5 minute updates, so a complete update of policy should be
spread over less than or equal to the same scheduled cycle time. Alternatively the cycle
for policy updates can be extended and the splaying can be even longer.
body executor control
{
splaytime => "4";
}
Scalability is about the internal and external architecture of the system, and the way that information flows around the highways and bottlenecks within it. As a distributed system, some of those are internal to the software, and some lie in the way it is used.
CFEngine allows users to build any external architecture, so the only intrinsic limitations are those internal to the software itself. Poor decisions about external architecture generally lead to greater problems that the internal limitations.
A number of techniques are used internally to bring efficiency and hence scalability in relation to policy.
ifelapsed timers on each promise, one can say how
often work-intensive checks are made.
| The greatest challenge for scalability is to reduce functional requirements to a description or model that uses patterns (i.e. general rules) to compress only what needs to be said about the policy into a comprehensible form. It is about identifying a necessary and sufficient level of complexity without over-simplification, and it is about not having to specify things that don't need to be specified. This is Knowledge Management. |
In the most scalable approach to management, each agent works 100% autonomously as a standalone system, requiring no communication with its peers, or with a central agency. Its policy is therefore constant and fixed.
If this model suits your organization, the operation of CFEngine is completely independent of the number of machines, so it exhibits perfect scaling with respect to the size of the infra-structure. However, this model is too simple for most sites, and its value lies in documenting the extreme end of the scalability scale, as an ideal to work towards when striving for efficiency.
As a self-healing system, CFEngine poses a low risk to loss of data. Most management data that are lost in an incident will recover automatically.
On clients, this workspace can be considered disposable, but many
users save public private key-pairs to preserve the `identity' of
hosts that have merely disk failures, etc.
Our general recommendation is to introduce as few network relationships as possible (make every system as autonomous as possible). Shared storage is more of a liability than an asset in general networks, as it increases the number of possible failure modes. Backup of the hub workspace is desirable, but not a show-stopper.
CFEngine 3 Nova is designed around the concept of a simple star network, i.e. a number of `client' machines bound together by a central hub. This is a commonly used architecture that is easy to understand. The hub architecture introduces a bottleneck, so we expect this to have a limited scalability as long as we cannot increase the power and the speed of the hub without limit.
To understand the external scalability of CFEngine management, we shall estimate how large a CFEngine system can grow using simple centralized management, in this star network pattern. This will force us to confront low level performance characteristics, where we try to extract the most from limited resources.
In a star network, all agents connect to a central hub to obtain possibly frequent updates. The challenge is to optimize this process2. This makes the central hub into a bottleneck. It becomes the weakest link in the chain of information, i.e. the star network has limitations that are nothing to do with CFEngine itself. The counterpoint is that the star network is very easy to comprehend, and thus it usually forms the starting point for most management frameworks.
| In the Community edition of CFEngine, updates travel only in one direction, from server to client. CFEngine Nova, adds to this the collection of data for reporting and analysis (CFDB), from client to hub. Thus the expected load on the server is the sum of both processes. |
We would like to answer two equivalent questions. Given a central hub with certain limitations, how many clients can it support? Conversely, given a number of hosts to support with a single hub, what capacity is required in system infrastructure to support it at a certain level?
There are actually two independent issues here. There is the scaling of the policy updates (served by the hub) and the scaling of the reporting updates (collected by the hub). Both of these processes compete for resources.
We start by setting some fundamental scales.
We choose deliberately a low value for network capacity. Even if more capacity is available, one does not typically expect to use it all for management overhead.
To a first approximation, the process scaling relationships are linear, as long as we stay far away from the region of resource contention at which a server will typically perform very quickly. Scalability is thus about having safe margins for worst case behaviour.
The number of threads t supported by a server satisfies:
st \le M
and yields a value for t, given fixed values for the hub's RAM and software build size. For a server with 1GB of memory, we have t \le 1024/12 \sim 80 threads. This will consume U \le 1MB of data per agent for a community host, and U\le 5MB for Nova to account for reporting.
The expected time-to-update \tau_\rm round satisfies:
U_\rm min/C \le \tau_\rm round\le U_\rm max/C
The actual values will normally by significantly less than this worst case, but he must plan for the possibility of update storms. The network capacity C = 1MBs^-1 suggests an expected time-to-update \tau_\rm round \le 2s (there and back) with a server-processing overhead. We shall take a conservative value of \tau_\rm round \le 10s for the maximum round trip request time.
Let's consider the policy/reporting update process, as this dominates the scaling behaviour of the software in terms of number of machines. Assuming that we can arrange for agents to distribute their updates over a single time interval \Delta t, with maximum possible entropy3, then we should be able to achieve a maximum number of scheduling slots \sigma:
\sigma = \Delta t/\tau_\rm round
Since the round-trip time can be higher or lower, depending on the size of the update, we can propose some approximate limits. \sigma_\max = 300/2, \sigma_\min = 300/10 per interval \Delta t.
The total number of updates that can complete in the \Delta t interval is thus, at fixed t:
N = \sigma t = \Delta t \over \tau_\rm roundt
If there are now t threads, then the total number of updates available must lie between the upper and lower bounds determined by \sigma:
2400 \le N \le 12,000.
So we can gauge a reasonable lower bound of 2000 machines from a single hub, with extremely conservative estimates of the environment. Note that when exceeding several thousands connections over a short time interval, other limitations of the operating system will normally start to play a role, e.g. the maximum number of allowed file descriptors. Further, comprehending a system of more than a few thousand machines is a challenge unless the system is extremely uniform.
In making each of these estimates, we are assuming that the hub machine will be working almost to capacity. Increasing its resources will naturally lead to improvements in performance.
A `star network' architecture has a single concentration of processing, centred around registration of incoming and outgoing hosts on the hub. Read/write activity is focused on two databases:
The scalablity of the hub depends on how efficiently reads and writes can be parallelized to these databases. Even with aggressive cachine, databases are disk-intensive and since disk access is typically the slowest or weakest link in the data flow chain, disk accesses will throttle the scalability of the hub the most.
CFEngine tries to support efficient parallelization by using multiple threads to serve and collect data, however access to a shared resource must always be serialized, so ultimately serial access to the disk will be the limiting factor. The CFEngine hub supports Linux systems. Simple SATA disks, USB and Firewire have very limited performance. To achieve the maximum scaling limit of a few thousand hosts per hub, users can invest in faster interfaces and disk speeds, or even solid state disk devices.
Because of the serialization, a heavily loaded MongoDB will eat up most of the resources on the hub, dominating the performance. Some performance tuning option strategies are discussed below. Clearly maximizing the amount of RAM on the hub is a way to improve the performance.
The time estimates for host updating used above include the latency of this database, but it is possible that there might be additional delays once the amount of data passes a certain limits. We currently have no data to support this assumption and await customer experiences either way.
Lookup times for data in the reports database increase with the number of host-keys, so the time required to generate certain reports (especially when searching through logs) must increase as the number of hosts increases.
When changes are made, many hosts will start downloading updated files. This can have a sudden impact on the network, as a lot of unexpected traffic is suddenly concentrated over a short interval of time. The contention from these multiple downloads can therefore make each download longer than it otherwise might have been, and this in turn makes the problem worse. The situation is analogous to disk thrashing.
| Once thrashing has started, it can cause greatly reduced performance and hosts might pass their `blue horizon threshold', appearing to disappear from the CFEngine Mission Portal. This does not mean the hosts are dead or even `out of control'. It only means that updates are taking too long according the tuning parameters. The default update horizon is. |
To assist the speed of policy processing by cf-agent, choose
class names evenly throughout the alphabet to make searching easier.
CFEngine arranges for indexing and cachine to be performed automatically.
CFEngine does not need a `high availability' architecture to be an effective management system. The software was designed to work with very low availability, and the designers highly recommend avoiding the introduction of dependencies that require such availability. In normal operation, CFEngine will be able to continue to repair systems without any contact with the outside world, until actual policy changes are made.
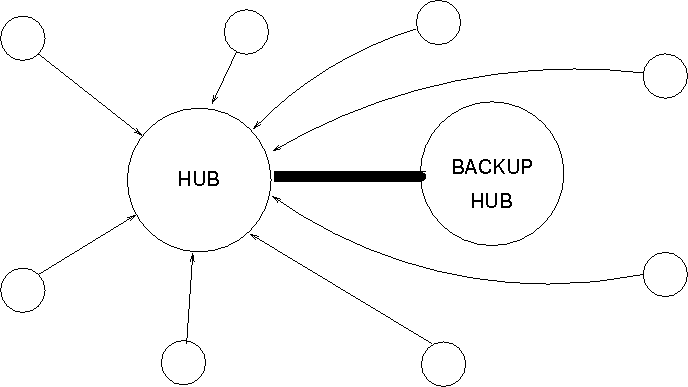
It is nonetheless possible to balance load and account for failures by multiplying the number of hubs/policy servers in a Nova star network. This only makes sense for the policy servers and reporting hubs, which are in principle single points of failure.
A simple way to balance client hosts across multiple servers is to split them into classes
using the select_class function4. Nothing else is needed to spread computers evenly
into a set of named buckets.
classes:
"selection" select_class => { "bucket1", "bucket2" };
This selects a particular class for each host from the list. A given
host will always map to the same class, thus allowing the rule for
policy updates to include copying from a personal `bucket' server.
body copy_from xyz
{
...
bucket1::
servers => { "server-abc-1.xyz.com", "failover.xyz.com" };
bucket2::
servers => { "server-abc-2.xyz.com", "failover.xyz.com" };
...
}
Note this method is not suitable for bootstrapping hosts in a hub configuration, since that requires a one to one relationship documented in the /var/cfengine/policy_server.dat resource.
A CFEngine reporting hub is a host that aggregates reports from all managed hosts in a Nova/Enterprise cluster. The purpose of aggregating reports is to have all the information in one place for searching, calibrating and comparing. The loss of a hub is an inconvenience rather than a problem, as the function of a hub is to make access to information about the system convenient and to enhance the knowledge of users.
It makes sense to back up some information from a reporting hub. Hub information is considered to be a mixture of two kinds of data:
The procedure for backing up the ephemeral data is:
cp /var/cfengine/cf_lastseen.db /backup
[1] We strongly recommend users to abandon the
idea that it is possible to have `instant' or `immediate'
updates. There is always some delay. It is more pragmatic to manage
that delay by making it predictable than to leave it to chance. [2] The estimates here are based on CFEngine core versions
3.1.2 and higher. [3] Maximum entropy means the most even or flat
distribution over the time interval, in this case. See, for instance,
Mark Burgess, Analytical Network and System Administration. [4] This feature was added in core 3.1.5.
Table of Contents
Footnotes